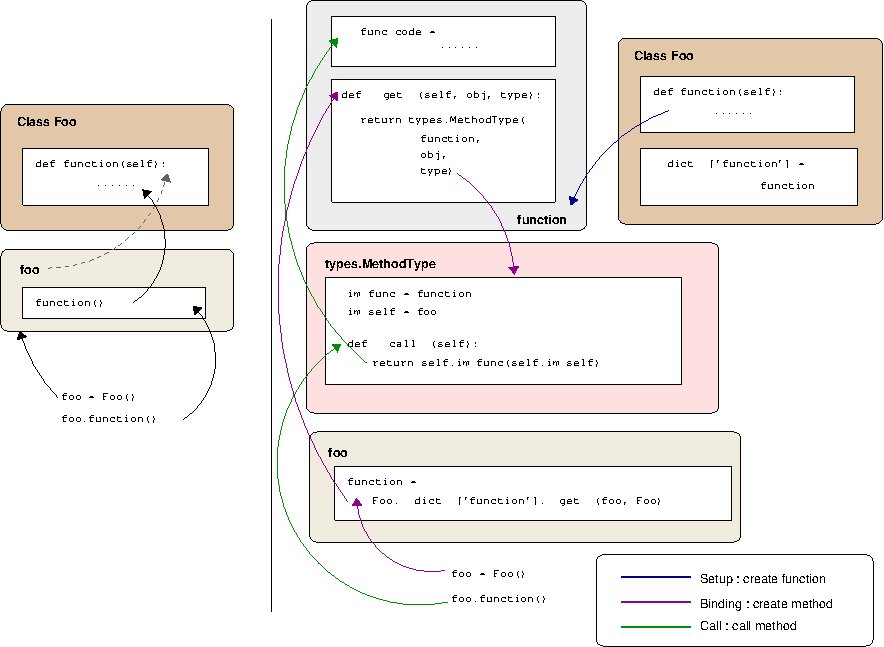
(this post was going to be about something else, but after getting this
far, I think it stands on its own as an introduction to dynamic linking)
The shared library is an integral part of a modern system, but often the
mechanisms behind the implementation are less well understood. There
are, of course, many guides to this sort of thing. Hopefully this adds
another perspective that resonates with someone.
Let's start at the beginning — - relocations are entries in binaries
that are left to be filled in later -- at link time by the toolchain
linker or at runtime by the dynamic linker. A relocation in a binary
is a descriptor which essentially says "determine the value of X, and
put that value into the binary at offset Y" — each relocation has a
specific type, defined in the ABI documentation, which describes
exactly how "determine the value of" is actually determined.
Here's the simplest example:
$ cat a.c
extern int foo;
int function(void) {
return foo;
}
$ gcc -c a.c
$ readelf --relocs ./a.o
Relocation section '.rel.text' at offset 0x2dc contains 1 entries:
Offset Info Type Sym.Value Sym. Name
00000004 00000801 R_386_32 00000000 foo
The value of foo is not known at the time you make a.o, so the
compiler leaves behind a relocation (of type R_386_32) which is
saying "in the final binary, patch the value at offset 0x4 in this
object file with the address of symbol foo". If you take a look at
the output, you can see at offset 0x4 there are 4-bytes of zeros just
waiting for a real address:
$ objdump --disassemble ./a.o
./a.o: file format elf32-i386
Disassembly of section .text:
00000000 <function>:
0: 55 push %ebp
1: 89 e5 mov %esp,%ebp
3: a1 00 00 00 00 mov 0x0,%eax
8: 5d pop %ebp
9: c3 ret
That's link time; if you build another object file with a value of foo
and build that into a final executable, the relocation can go away. But
there is a whole bunch of stuff for a fully linked executable or
shared-library that just can't be resolved until runtime. The major
reason, as I shall try to explain, is position-independent code (PIC).
When you look at an executable file, you'll notice it has a fixed load
address
$ readelf --headers /bin/ls
[...]
ELF Header:
[...]
Entry point address: 0x8049bb0
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
[...]
LOAD 0x000000 0x08048000 0x08048000 0x16f88 0x16f88 R E 0x1000
LOAD 0x016f88 0x0805ff88 0x0805ff88 0x01543 0x01543 RW 0x1000
This is not position-independent. The code section (with permissions
R E; i.e. read and execute) must be loaded at virtual address
0x08048000, and the data section (RW) must be loaded above that
at exactly 0x0805ff88.
This is fine for an executable, because each time you start a new
process (fork and exec) you have your own fresh address space.
Thus it is a considerable time saving to pre-calculate addresses from
and have them fixed in the final output (you can make
position-independent executables, but that's another story).
This is not fine for a shared library (.so). The whole point of a
shared library is that applications pick-and-choose random permutations
of libraries to achieve what they want. If your shared library is built
to only work when loaded at one particular address everything may be
fine — until another library comes along that was built also using that
address. The problem is actually somewhat tractable — you can just
enumerate every single shared library on the system and assign them all
unique address ranges, ensuring that whatever combinations of library
are loaded they never overlap. This is essentially what prelinking
does (although that is a hint, rather than a fixed, required address
base). Apart from being a maintenance nightmare, with 32-bit systems you
rapidly start to run out of address-space if you try to give every
possible library a unique location. Thus when you examine a shared
library, they do not specify a particular base address to be loaded at:
$ readelf --headers /lib/libc.so.6
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
[...]
LOAD 0x000000 0x00000000 0x00000000 0x236ac 0x236ac R E 0x1000
LOAD 0x023edc 0x00024edc 0x00024edc 0x0015c 0x001a4 RW 0x1000
Shared libraries also have a second goal — code sharing. If a hundred
processes use a shared library, it makes no sense to have 100 copies of
the code in memory taking up space. If the code is completely read-only,
and hence never, ever, modified, then every process can share the same
code. However, we have the constraint that the shared library must still
have a unqiue data instance in each process. While it would be possible
to put the library data anywhere we want at runtime, this would require
leaving behind relocations to patch the code and inform it where to
actually find the data — destroying the always read-only property of the
code and thus sharability. As you can see from the above headers, the
solution is that the read-write data section is always put at a known
offset from the code section of the library. This way, via the magic of
virtual-memory, every process sees its own data section but can share
the unmodified code. All that is needed to access data is some simple
maths; address of thing I want = my current address + known fixed
offset.
Well, simple maths is all relative! "My current address" may or may not
be easy to find. Consider the following:
$ cat test.c
static int foo = 100;
int function(void) {
return foo;
}
$ gcc -fPIC -shared -o libtest.so test.c
So foo will be in data, at a fixed offset from the code in
function, and all we need to do is find it! On amd64, this is quite
easy, check the disassembly:
000000000000056c <function>:
56c: 55 push %rbp
56d: 48 89 e5 mov %rsp,%rbp
570: 8b 05 b2 02 20 00 mov 0x2002b2(%rip),%eax # 200828 <foo>
576: 5d pop %rbp
This says "put the value at offset 0x2002b2 from the current instruction
pointer (%rip) into %eax. That's it — we know the data is at
that fixed offset so we're done. i386, on the other hand, doesn't have
the ability to offset from the current instruction pointer. Some
trickery is required there:
0000040c <function>:
40c: 55 push %ebp
40d: 89 e5 mov %esp,%ebp
40f: e8 0e 00 00 00 call 422 <__i686.get_pc_thunk.cx>
414: 81 c1 5c 11 00 00 add $0x115c,%ecx
41a: 8b 81 18 00 00 00 mov 0x18(%ecx),%eax
420: 5d pop %ebp
421: c3 ret
00000422 <__i686.get_pc_thunk.cx>:
422: 8b 0c 24 mov (%esp),%ecx
425: c3 ret
The magic here is __i686.get_pc_thunk.cx. The architecture does not
let us get the current instruction address, but we can get a known fixed
address — the value __i686.get_pc_thunk.cx pushes into cx is the
return value from the call, i.e in this case 0x414. Then we can
do the maths for the add instruction; 0x115c + 0x414 = 0x1570,
the final move goes 0x18 bytes past that to 0x1588 ... checking
the disassembly
00001588 <global>:
1588: 64 00 00 add %al,%fs:(%eax)
i.e., the value 100 in decimal, stored in the data section.
We are getting closer, but there are still some issues to deal with. If
a shared library can be loaded at any address, then how does an
executable, or other shared library, know how to access data or call
functions in it? We could, theoretically, load the library and patch up
any data references or calls into that library; however as just
described this would destroy code-sharability. As we know, all problems
can be solved with a layer of indirection, in this case called global
offset table or GOT.
Consider the following library:
$ cat test.c
extern int foo;
int function(void) {
return foo;
}
$ gcc -shared -fPIC -o libtest.so test.c
Note this looks exactly like before, but in this case the foo is
extern; presumably provided by some other library. Let's take a
closer look at how this works, on amd64:
$ objdump --disassemble libtest.so
[...]
00000000000005ac <function>:
5ac: 55 push %rbp
5ad: 48 89 e5 mov %rsp,%rbp
5b0: 48 8b 05 71 02 20 00 mov 0x200271(%rip),%rax # 200828 <_DYNAMIC+0x1a0>
5b7: 8b 00 mov (%rax),%eax
5b9: 5d pop %rbp
5ba: c3 retq
$ readelf --sections libtest.so
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[...]
[20] .got PROGBITS 0000000000200818 00000818
0000000000000020 0000000000000008 WA 0 0 8
$ readelf --relocs libtest.so
Relocation section '.rela.dyn' at offset 0x418 contains 5 entries:
Offset Info Type Sym. Value Sym. Name + Addend
[...]
000000200828 000400000006 R_X86_64_GLOB_DAT 0000000000000000 foo + 0
The disassembly shows that the value to be returned is loaded from an
offset of 0x200271 from the current %rip; i.e. 0x0200828.
Looking at the section headers, we see that this is part of the .got
section. When we examine the relocations, we see a R_X86_64_GLOB_DAT
relocation that says "find the value of symbol foo and put it into
address 0x200828.
So, when this library is loaded, the dynamic loader will examine the
relocation, go and find the value of foo and patch the .got
entry as required. When it comes time for the code loads to load that
value, it will point to the right place and everything just works;
without having to modify any code values and thus destroy code
sharability.
This handles data, but what about function calls? The indirection used
here is called a procedure linkage table or PLT. Code does not call an
external function directly, but only via a PLT stub. Let's examine
this:
$ cat test.c
int foo(void);
int function(void) {
return foo();
}
$ gcc -shared -fPIC -o libtest.so test.c
$ objdump --disassemble libtest.so
[...]
00000000000005bc <function>:
5bc: 55 push %rbp
5bd: 48 89 e5 mov %rsp,%rbp
5c0: e8 0b ff ff ff callq 4d0 <foo@plt>
5c5: 5d pop %rbp
$ objdump --disassemble-all libtest.so
00000000000004d0 <foo@plt>:
4d0: ff 25 82 03 20 00 jmpq *0x200382(%rip) # 200858 <_GLOBAL_OFFSET_TABLE_+0x18>
4d6: 68 00 00 00 00 pushq $0x0
4db: e9 e0 ff ff ff jmpq 4c0 <_init+0x18>
$ readelf --relocs libtest.so
Relocation section '.rela.plt' at offset 0x478 contains 2 entries:
Offset Info Type Sym. Value Sym. Name + Addend
000000200858 000400000007 R_X86_64_JUMP_SLO 0000000000000000 foo + 0
So, we see that function makes a call to code at 0x4d0.
Disassembling this, we see an interesting call, we jump to the value
stored in 0x200382 past the current %rip (i.e. 0x200858),
which we can then see the relocation for — the symbol foo.
It is interesting to keep following this through; let's look at the
initial value that is jumped to:
$ objdump --disassemble-all libtest.so
Disassembly of section .got.plt:
0000000000200840 <.got.plt>:
200840: 98 cwtl
200841: 06 (bad)
200842: 20 00 and %al,(%rax)
...
200858: d6 (bad)
200859: 04 00 add $0x0,%al
20085b: 00 00 add %al,(%rax)
20085d: 00 00 add %al,(%rax)
20085f: 00 e6 add %ah,%dh
200861: 04 00 add $0x0,%al
200863: 00 00 add %al,(%rax)
200865: 00 00 add %al,(%rax)
...
Unscrambling 0x200858 we see its initial value is 0x4d6 — i.e.
the next instruction! Which then pushes the value 0 and jumps to
0x4c0. Looking at that code we can see it pushes a value from the
GOT, and then jumps to a second value in the GOT:
00000000000004c0 <foo@plt-0x10>:
4c0: ff 35 82 03 20 00 pushq 0x200382(%rip) # 200848 <_GLOBAL_OFFSET_TABLE_+0x8>
4c6: ff 25 84 03 20 00 jmpq *0x200384(%rip) # 200850 <_GLOBAL_OFFSET_TABLE_+0x10>
4cc: 0f 1f 40 00 nopl 0x0(%rax)
What's going on here? What's actually happening is lazy binding — by
convention when the dynamic linker loads a library, it will put an
identifier and resolution function into known places in the GOT.
Therefore, what happens is roughly this: on the first call of a
function, it falls through to call the default stub, which loads the
identifier and calls into the dynamic linker, which at that point has
enough information to figure out "hey, this libtest.so is trying to
find the function foo". It will go ahead and find it, and then patch
the address into the GOT such that the next time the original PLT
entry is called, it will load the actual address of the function, rather
than the lookup stub. Ingenious!
Out of this indirection falls another handy thing — the ability to
modify the symbol binding order. LD_PRELOAD, for example, simply
tells the dynamic loader it should insert a library as first to be
looked-up for symbols; therefore when the above binding happens if the
preloaded library declares a foo, it will be chosen over any other
one provided.
In summary — code should be read-only always, and to make it so that you
can still access data from other libraries and call external functions
these accesses are indirected through a GOT and PLT which live at
compile-time known offsets.
In a future post I'll discuss some of the security issues around this
implementation, but that post won't make sense unless I can refer back
to this one :)