You work with Python for a while and you'll become familiar with printing a method and getting
<bound method Foo.function of <__main__.Foo instance at 0xb736960c>>
I think there is room for one more explanation on the internet, since I've never seen it diagrammed out (maybe for good reason!).
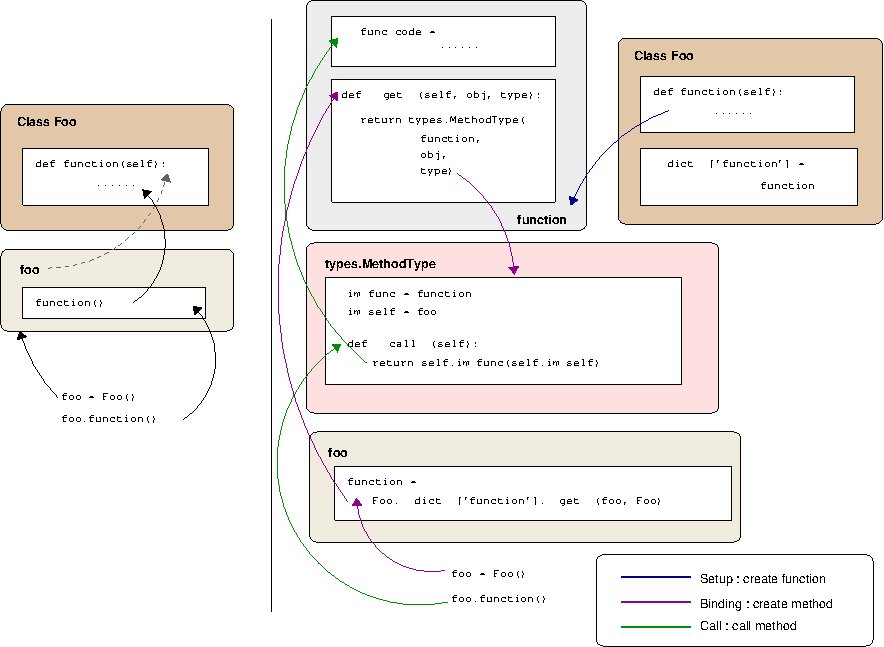
In the above diagram on the left, we have the fairly simple conceptual model of a class with a function. One naturally tends to think of the function as a part of the class and your instance calls into that function. This is conceptually correct, but a little abstracted from what's actually happening.
The right attempts to illustrate the underlying process in some more depth. The first step, on the top right, is building something like the following:
class Foo():
def function(self):
print "hi!"
As this illustrates, the above code results in two things happening; firstly a function object for function is created and secondly the __dict__ attribute of the class is given a key function that points to this function object.
Now the thing about this function object is that it implements the descriptor protocol. In short, if an object implements a __get__ function; then when that object is accessed as an attribute of an object the __get__ function is called. You can read up on the descriptor protocol, but the important part to remember is that it passes in the context from which it is called; that is the object that is calling the function.
So, for example, when we then do the following:
f = Foo()
f.function()
what happens is that we get the attribute function of f and then call it. f above doesn't actually know anything about function as such — what it does know is its class inheritance and so Python goes searching the parent's class __dict__ to try and find the function attribute. It finds this, and as per the descriptor protocol when the attribute is accessed it calls the __get__ function of the underlying function object.
What happens now is that the function's __get__ method returns essentially a wrapper object that stores the information to bind the function to the object. This wrapper object is of type types.MethodType and you can see it stores some important attributes in the object — im_func which is the function to call, and im_self which is the object who called it. Passing the object through to im_self is how function gets it's first self argument (the calling object).
So when you print the value of f.function() you see it report itself as a bound method. So hopefully this illustrates that a bound method is a just a special object that knows how to call an underlying function with context about the object that's calling it.
To try and make this a little more concrete, consider the following program:
import types
class Foo():
def function(self):
print "hi!"
f = Foo()
# this is a function object
print Foo.__dict__['function']
# this is a method as returned by
# Foo.__dict__['function'].__get__()
print f.function
# we can check that this is an instance of MethodType
print type(f.function) == types.MethodType
# the im_func field of the MethodType is the underlying function
print f.function.im_func
print Foo.__dict__['function']
# these are the same object
print f.function.im_self
print f
Running this gives output something like
$ python ./foo.py <function function at 0xb73540d4> <bound method Foo.function of <__main__.Foo instance at 0xb736960c>> True <function function at 0xb73540d4> <function function at 0xb73540d4> <__main__.Foo instance at 0xb72c060c> <__main__.Foo instance at 0xb72c060c>
To pull it apart; we can see that Foo.__dict__['function'] is a function object, but then f.function is a bound method. The bound method's im_func is the underlying function object, and the im_self is the object f: thus im_func(im_self) is calling function with the correct object as the first argument self.
So the main point is to kind of shift thinking about a function as some particular intrinsic part of a class, but rather as a separate object abstracted from the class that gets bound into an instance as required. The class is in some ways a template and namespacing tool to allow you to find the right function objects; it doesn't actually implement the functions as such.
There is plenty more information if you search for "descriptor protocol" and Python binding rules and lots of advanced tricks you can play. But hopefully this is a useful introduction to get an initial handle on what's going on!
