A comment pointed out that the original article from 2008 made a few
simplifications that were a bit misleading, so I have taken some time
to update this. Thanks for the feedback.
If you've ever tried to link non-position independent code into a shared
library on x86-64, you should have seen a fairly cryptic error about
invalid relocations and missing symbols. Hopefully this will clear it up
a little.
Let's start with a small program to illustrate.
int global = 100;
int function(int i) {
return i + global;
}
Firstly, inspect the disassembley of this function:
$gcc -c function.c
$objdump --disassemble function.o
0000000000000000 <function>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 89 7d fc mov %edi,-0x4(%rbp)
7: 8b 05 00 00 00 00 mov 0x0(%rip),%eax # d <function+0xd>
d: 03 45 fc add -0x4(%rbp),%eax
10: c9 leaveq
11: c3 retq
Lets just go through that for clarity:
- 0,1: save rbp to the stack and save the stack pointer
(rsp) to rbp. This common stanza is setting up the frame
pointer, which is essentially a rule used by debuggers (mostly) to
keep track of the base of the stack. It's not important for now.
- 4:Move the value from edi to 4 bytes below the stack pointer.
This is moving the first argument (int i) into the "red-zone", a
128-byte scratch area each function has reserved below the stack
pointer.
- 7,d: Move the value at offset 0 from the current
instruction pointer (rip) into eax (by convention the return
value is left in register eax). Then add the incoming argument to
it (retrieved from the scratch area); i.e. return global + i
The IP relative move is really the trick here. We know from the code
that it has to move the value of the global variable here. The zero
value is simply a place holder - the compiler currently does not
determine the required address (i.e. how far away from the instruction
pointer the memory holding the global variable is). It leaves behind
a relocation -- a note that says to the linker "you should determine
the correct address of foo (global in our case), and then patch
this bit of the code to point to that addresss".
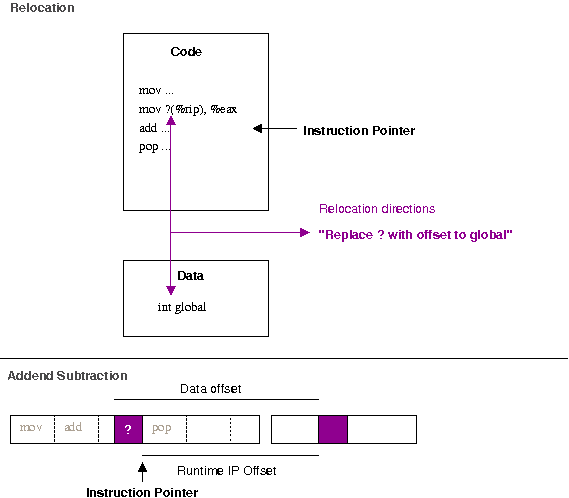
The top portion of the image above gives some idea of how it works. We
can examine relocations in binaries with the readelf tool.
$ readelf --relocs ./function.o
Relocation section '.rela.text' at offset 0x518 contains 1 entries:
Offset Info Type Sym. Value Sym. Name + Addend
000000000009 000800000002 R_X86_64_PC32 0000000000000000 global + fffffffffffffffc
There are many different types of relocations for different situations;
the exact rules for different relocation types are described in the ABI
documentation for the architecture. The R_X86_64_PC32 relocation is
defined as "the base of the section the symbol is within, plus the
symbol value, plus the addend". The addend makes it look more tricky
than it is; remember that when an instruction is executing the
instruction pointer points to the next instruction to be executed.
Therefore, to correctly find the data relative to the instruction
pointer, we need to subtract the extra. This can be seen more clearly
when layed out in a linear fashion (as in the bottom of the above
diagram).
If you try and build a shared object (dynamic library) with an object
file with this type of relocation, you should get something like:
$ gcc -shared function.c
/usr/bin/ld: /tmp/ccQ2ttcT.o: relocation R_X86_64_32 against `a local symbol' can not be used when making a shared object; recompile with -fPIC
/tmp/ccQ2ttcT.o: could not read symbols: Bad value
collect2: ld returned 1 exit status
If you look back at the disassembly, we notice that the
R_X86_64_32 relocation has left only 4-bytes (32-bits) of space
left for the relocation entry (the zeros in 7: 8b 15 00 00 00 00).
So why does this matter when you're creating a shared library? The
first thing to remember is that in a shared library situation, we can
not depend on the local value of global actually being the one we
want. Consider the following example, where we override the value of
global with a LD_PRELOAD library.
$ cat function.c
int global = 100;
int function(int i) {
return i + global;
}
$ gcc -fPIC -shared -o libfunction.so function.c
$ cat preload.c
int global = 200;
$ gcc -shared preload.c -o libpreload.so
$ cat program.c
#include <stdio.h>
int function(int i);
int main(void) {
printf("%d\n", function(10));
}
$ gcc -L. -lfunction program.c -o program
$ LD_LIBRARY_PATH=. ./program
110
$ LD_PRELOAD=libpreload.so LD_LIBRARY_PATH=. ./program
210
If the code in libfunction.so were to have a fixed offset into its
own data section, it will not be able to be overridden at run-time by
the value provided by libpreload.so. Additionally, there are only
4-bytes available to patch in for the address of global -- since a
shared library could conceivably be loaded anywhere in the 64-bit
(8-byte) address space we therefore need 8-bytes of space to cover
ourselves for all possible addresses global might turn up at.
The two basic possibilities for an object file are to be either linked
into an executable or linked into a shared-library. In the executable
case, the value of global will be in the exectuable's data
section, which should definitely be reachable with a 32-bit offset of
the current instruction-pointer. The instruction-pointer relative
address can simply be patched in and the executable is finalised.
But what about the shared-library case, where we know the value of
global could essentially be anywhere within the 64-bit address
space? It is possible to leave 8-bytes of space for the address of
global, by telling gcc to use the large-code model. e.g.
$ gcc -c -mcmodel=large function.c
$ objdump --disassemble ./function.o
./function.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <function>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 89 7d fc mov %edi,-0x4(%rbp)
7: 48 b8 00 00 00 00 00 movabs $0x0,%rax
e: 00 00 00
11: 8b 10 mov (%rax),%edx
13: 8b 45 fc mov -0x4(%rbp),%eax
16: 01 d0 add %edx,%eax
18: 5d pop %rbp
19: c3 retq
However, this creates a problem if you really want to share this
code. By having to patch in an address of global directly, this
means the run-time code above does not remain unchanged. Two
separate processes therefore can't share this code -- they each need
separate copies that are identical but for their own addresses of
global patched into it.
By enabling Position Independent Code (PIC, with the flag -fPIC)
you can ensure the code remains share-able. PIC means that the output
binary does not expect to be loaded at a particular base address, but
is happy being put anywhere in memory (compare the output of readelf
--segments on a binary such as /bin/ls to that of any shared
library). This is obviously critical for implementing lazy-loading
(i.e. only loaded when required) shared-libraries, where you may have
many libraries loaded in essentially any order at any location.
Of course, any problem in computer science can be solved with a layer
of abstraction and that is essentially what is done when compiling
with -fPIC. To examine this case, let's see what happens with PIC
turned on.
$ gcc -fPIC -shared -c function.c
$ objdump --disassemble ./function.o
./function.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <function>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 89 7d fc mov %edi,-0x4(%rbp)
7: 48 8b 05 00 00 00 00 mov 0x0(%rip),%rax # e <function+0xe>
e: 8b 00 mov (%rax),%eax
10: 03 45 fc add -0x4(%rbp),%eax
13: c9 leaveq
14: c3 retq
It's almost the same! We setup the frame pointer with the first two
instructions as before. We push the first argument into memory in the
pre-allocated "red-zone" as before. Then, however, we do an IP relative
load of an address into rax. Next we de-reference this into eax
(e.g. eax = *rax in C) before adding the incoming argument to it and
returning.
$ readelf --relocs ./function.o
Relocation section '.rela.text' at offset 0x550 contains 1 entries:
Offset Info Type Sym. Value Sym. Name + Addend
00000000000a 000800000009 R_X86_64_GOTPCREL 0000000000000000 global + fffffffffffffffc
The magic here is again in the relocations. Notice this time we have a
P_X86_64_GOTPCREL relocation. This says "replace the data at offset
0xa with the global offset table (GOT) entry of global.
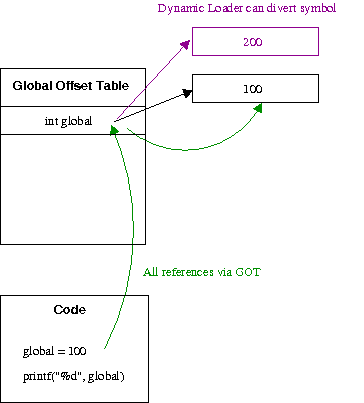
As shown above, the GOT ensures the abstraction required so symbols
can be diverted as expected. Each entry is essentially a pointer to
the real data (hence the extra dereference in the code above). Since
we can assume the GOT is at a fixed offset from the program code
within plus or minus 2Gib, the code can use a 32-bit IP relative
address to gain access to the table entries.
So, taking a look a the final shared-library binary we see a final
offset hard-coded
$ gcc -shared -fPIC -o libfunction.so function.c
$ objdump --disassemble ./libfunction.so
00000000000006b0 <function>:
6b0: 55 push %rbp
6b1: 48 89 e5 mov %rsp,%rbp
6b4: 89 7d fc mov %edi,-0x4(%rbp)
6b7: 48 8b 05 8a 02 20 00 mov 0x20028a(%rip),%rax # 200948 <_DYNAMIC+0x1d8>
6be: 8b 10 mov (%rax),%edx
6c0: 8b 45 fc mov -0x4(%rbp),%eax
6c3: 01 d0 add %edx,%eax
6c5: 5d pop %rbp
6c6: c3 retq
6c7: 90 nop
Every process who wants to share this code just needs to make sure
they have their unique address of global at 0x20028a(%rip).
Since each process has a separate address-space, this means they can
all have different values for global but share the same code!
Thus the default of the small-code model is sensible. It is
exceedingly rare for an executable to need more than 4-byte offsets
for a relative access to a variable in it's data region, so using a
full 8-byte value would just be a waste of space. Although leaving
8-bytes would allow access to the variable anywhere in the 64-bit
address space; when building a shared library, you really want to use
-fPIC to ensure the library can actually be shared, which
introduces a different relocation and access to data via the GOT.
This should explain why gcc -shared function.c works on x86-32,
but does not work on x86-64. Inspecting the code reveals why:
$ objdump --disassemble ./function.o
00000000 <function>:
0: 55 push %ebp
1: 89 e5 mov %esp,%ebp
3: a1 00 00 00 00 mov 0x0,%eax
8: 03 45 08 add 0x8(%ebp),%eax
b: 5d pop %ebp
c: c3 ret
$ readelf --relocs ./function.o
Relocation section '.rel.text' at offset 0x2ec contains 1 entries:
Offset Info Type Sym.Value Sym. Name
00000004 00000701 R_386_32 00000000 global
We start out the same, with the first two instructions setting up the
frame pointer. However, next we load a memory value into eax -- as
we can see from the relocation information, the address of global.
Next we add the incoming argument from the stack (0x8(%ebp)) to
the value in this memory location; implicitly dereferencing it. But
since we only have a 32-bit address-space, the 4-bytes allocated is
enough to access any possible address. So while this can work, you're
not creating position-independent code and hence not enabling
code-sharing.
The disadvantage of PIC code is that you require "bouncing" through
the GOT, which requires more loads and reads to find an address than
directly referencing it. However, if your program is at the point
that this is becoming a performance issue you're probably not reading
this blog!
Hopefully, this helps clear up that possibly cryptic error message.
Further searches around position-independent code, global-offset
tables and code-sharing should also yield you more information if it
remains unclear.