In a prior post, I gave an overview of the OpenStack CI system and how jobs were started. In that I said
(It is a gross oversimplification, but for the purposes of OpenStack CI, Jenkins is pretty much used as a glorified ssh/scp wrapper. Zuul Version 3, under development, is working to remove the need for Jenkins to be involved at all).
Well some recent security issues with Jenkins and other changes has led to a roll-out of what is being called Zuul 2.5, which has indeed removed Jenkins and makes extensive use of Ansible as the basis for running CI tests in OpenStack. Since I already had the diagram, it seems worth updating it for the new reality.
OpenStack CI Overview
While previous post was really focused on the image-building components of the OpenStack CI system, overview is the same but more focused on the launchers that run the tests.
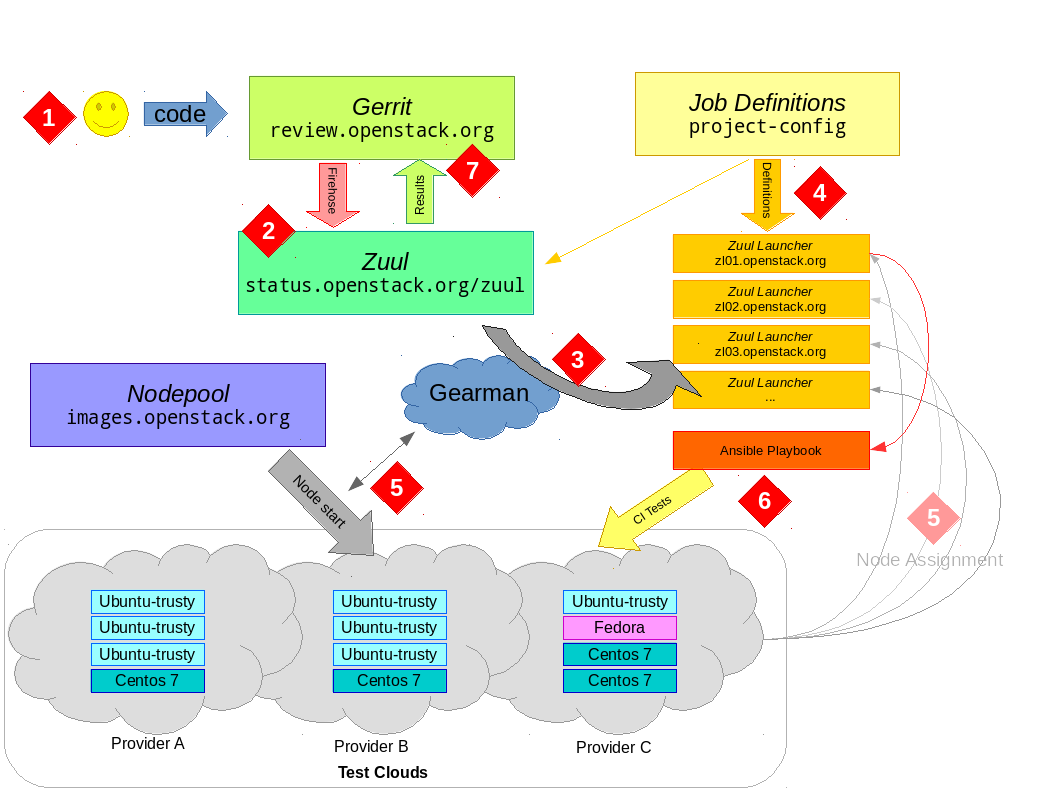
The process starts when a developer uploads their code to gerrit via the git-review tool. There is no further action required on their behalf and the developer simply waits for results of their jobs.
Gerrit provides a JSON-encoded "fire-hose" output of everything happening to it. New reviews, votes, updates and more all get sent out over this pipe. Zuul is the overall scheduler that subscribes itself to this information and is responsible for managing the CI jobs appropriate for each change.
Zuul has a configuration that tells it what jobs to run for what projects. Zuul can do lots of interesting things, but for the purposes of this discussion we just consider that it puts the jobs it wants run into gearman for a launcher to consume. gearman is a job-server; as they explain it "[gearman] provides a generic application framework to farm out work to other machines or processes that are better suited to do the work". Zuul puts into gearman basically a tuple (job-name, node-type) for each job it wants run, specifying the unique job name to run and what type of node it should be run on.
A group of Zuul launchers are subscribed to gearman as workers. It is these Zuul launchers that will consume the job requests from the queue and actually get the tests running. However, a launcher needs two things to be able to run a job — a job definition (what to actually do) and a worker node (somewhere to do it).
The first part — what to do — is provided by job-definitions stored in external YAML files. The Zuul launcher knows how to process these files (with some help from Jenkins Job Builder, which despite the name is not outputting XML files for Jenkins to consume, but is being used to help parse templates and macros within the generically defined job definitions). Each Zuul launcher gets these definitions pushed to it constantly by Puppet, thus each launcher knows about all the jobs it can run automatically. Of course Zuul also knows about these same job definitions; this is the job-name part of the tuple we said it put into gearman.
The second part — somewhere to run the test — takes some more explaining. To the next point...
Several cloud companies donate capacity in their clouds for OpenStack to run CI tests. Overall, this capacity is managed by a customized management tool called nodepool (you can see the details of this capacity at any given time by checking the nodepool configuration). Nodepool watches the gearman queue and sees what requests are coming out of Zuul. It looks at node-type of jobs in the queue (i.e. what platform the job has requested to run on) and decides what types of nodes need to start and which cloud providers have capacity to satisfy demand.
Nodepool will start fresh virtual machines (from images built daily as described in the prior post), monitor their start-up and, when they're ready, put a new "assignment job" back into gearman with the details of the fresh node. One of the active Zuul launchers will pick up this assignment job and register the new node to itself.
At this point, the Zuul launcher has what it needs to actually get jobs started. With an fresh node registered to it and waiting for something to do, the Zuul launcher can advertise its ability to consume one of the waiting jobs from the gearman queue. For example, if a ubuntu-trusty node is provided to the Zuul launcher, the launcher can now consume from gearman any job it knows about that is intended to run on an ubuntu-trusty node type. If you're looking at the launcher code this is driven by the NodeWorker class — you can see this being created in response to an assignment via LaunchServer.assignNode.
To actually run the job — where the "job hits the metal" as it were — the Zuul launcher will dynamically construct an Ansible playbook to run. This playbook is a concatenation of common setup and teardown operations along with the actual test scripts the jobs wants to run. Using Ansible to run the job means all the flexibility an orchestration tool provides is now available to the launcher. For example, there is a custom console streamer library that allows us to live-stream the console output for the job over a plain TCP connection, and there is the possibility to use projects like ARA for visualisation of CI runs. In the future, Ansible will allow for better coordination when running multiple-node testing jobs — after all, this is what orchestration tools such as Ansible are made for! While the Ansible run can be fairly heavyweight (especially when you're talking about launching thousands of jobs an hour), the system scales horizontally with more launchers able to consume more work easily.
When checking your job results on logs.openstack.org you will see a _zuul_ansible directory now which contains copies of the inventory, playbooks and other related files that the launcher used to do the test run.
Eventually, the test will finish. The Zuul launcher will put the result back into gearman, which Zuul will consume (log copying is interesting but a topic for another day). The testing node will be released back to nodepool, which destroys it and starts all over again — nodes are not reused and also have no sensitive details on them, as they are essentially publicly accessible. Zuul will wait for the results of all jobs for the change and post the result back to Gerrit; it either gives a positive vote or the dreaded negative vote if required jobs failed (it also handles merges to git, but that is also a topic for another day).
Work will continue within OpenStack Infrastructure to further enhance Zuul; including better support for multi-node jobs and "in-project" job definitions (similar to the https://travis-ci.org/ model); for full details see the spec.