Today I started wondering what actually happens when you plug in a USB
device. The little tour below goes from starting the USB subsystem to
plugging something in, and I hope it is reasonably accurate. This entry
is probably best read with a copy of the Linux kernel handy.
Linux USB Core, lower-layers
We can start our tour right at the very bottom in the heart of the USB
core.
Things really start at the USB initialisation function in
drivers/usb/core/usb.c:usb_init(). The first interesting call is to
drivers/base/bus.c:bus_register(). We see that it passes as
struct bus_type which looks like:
struct bus_type usb_bus_type = {
.name = "usb",
.match = usb_device_match,
.uevent = usb_uevent,
.suspend = usb_suspend,
.resume = usb_resume,
};
This is registering a new type of bus with the Linux driver core
framework. The bus doesn't have much yet, just a name and some helper
functions, but registering a bus sets up the kobject hierarchy that
gets exported through /sys/bus/ (/sys/bus/usb in this case) and
will allow the further hierarchical building of devices underneath by
attaching them as the system runs. This is like the root directory of
the USB system.
Your desktop/laptop/palmtop etc has a host controller which directly
interfaces to USB devices; common types are UHCI, OHCI and EHCI. The
drivers for these various types of controllers live in
drivers/usb/host. These controllers are similar but different, so to
minimise code duplication Linux has a Host Controller Driver framework
(drivers/usb/core/hcd.c) which abstracts most of the common
operations from the host controller driver.
The HCD layer does this by keeping a struct usb_hcd
(drivers/usb/core/hcd.h) with all common information in it for a
host controller. Each of host controller drivers fills out a
struct hc_driver for its hardware dependent operations, as per below
(taken from the UHCI driver)
static const struct hc_driver uhci_driver = {
.description = hcd_name,
.product_desc = "UHCI Host Controller",
.hcd_priv_size = sizeof(struct uhci_hcd),
/* Generic hardware linkage */
.irq = uhci_irq,
.flags = HCD_USB11,
/* Basic lifecycle operations */
.reset = uhci_init,
.start = uhci_start,
#ifdef CONFIG_PM
.suspend = uhci_suspend,
.resume = uhci_resume,
.bus_suspend = uhci_rh_suspend,
.bus_resume = uhci_rh_resume,
#endif
.stop = uhci_stop,
.urb_enqueue = uhci_urb_enqueue,
.urb_dequeue = uhci_urb_dequeue,
.endpoint_disable = uhci_hcd_endpoint_disable,
.get_frame_number = uhci_hcd_get_frame_number,
.hub_status_data = uhci_hub_status_data,
.hub_control = uhci_hub_control,
};
USB overview
It might be helpful to clarify a few USB concepts now. A USB device
defines a group of end-points, where are grouped together into an
interface. An end-point can be either "IN" or "OUT", and sends data in
one direction only. End-points can have a number of different types:
- Control end-points are for configuring the device, etc.
- Interrupt end-points are for transferring small amounts of data.
They have higher priority than ...
- Bulk end-points, who can transfer more data but do not get
guaranteed time constraints.
- Isochronous transfers are high-priority real-time transfers, but
if they are missed they are not re-tried. This is for streaming data
like video or audio where there is no point sending data again.
There can be many interfaces (made of multiple end-points) and
interfaces are grouped into "configurations". Most devices only have a
single configuration.
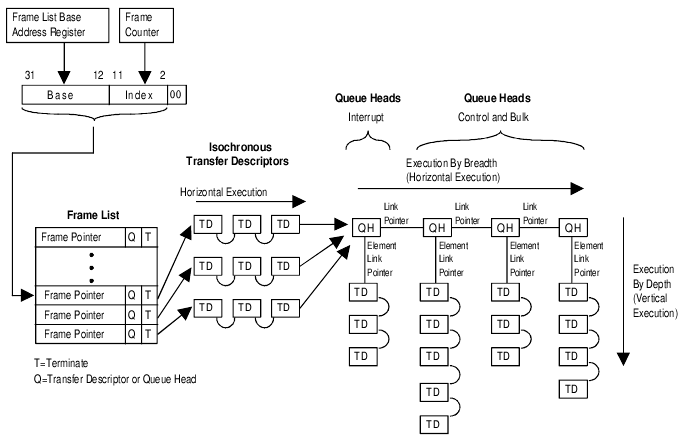
You can see how this works at the host controller level with the above
diagram clagged from the Intel UHCI documents. The controller has a
"frame" register which is incremented every millisecond. Each frame
pointer points to a queue of "transfer descriptors". The driver needs to
schedule this work so that 90% of the time is given to isochronous data,
and 10% left for control data. Should any time remain, the bulk data is
transferred. You can see that any transfer descriptor for isochronous
data will not be retried, but other data sits in a queue so it is never
lost.
The USB layer communicates through USB request blocks, or URBs. A
URB contains information about what end-point this request relates to,
data, any related information or attributes and a call-back function to
be called when the URB is complete. Drivers submit URBs to the USB core,
which manages them in co-ordination with the USB host (see the
urb_enqueue functions provided by the host driver). Your data gets
sent off to the USB device by the USB core, and when its done your
call-back is triggered.
Root Hub
There is one more element quite fundamental to the USB core, which is
the hub -- all USB devices plug into a hub. The USB controller
implements a root hub; you can have multiple root hubs in a machine,
and other hubs can then connect to root hubs. The hub driver lives in
drivers/usb/core/hub.c. The USB initialisation function starts up
the khubd thread (drivers/usb/core/hub.c:usb_hub_init()) which
waits for and handles USB events, but we will return to that later.
The hub driver is the first USB driver to be setup, so by examining how
that works we can get a feel for how other drivers work.
The hub driver setup starts in drivers/usb/core/usb.c:usb_init()
where the drivers/usb/core/hub.c:usb_hub_init() function is called.
This calls drivers/usb/core/driver.c:usb_register_driver() which
adds itself to the USB bus we mentioned previously. This sets up
usb_probe_device() to handle any probe events from the Linux driver
core. At this point the hub driver is ready to claim anything that looks
like a USB hub.
The root hub setup phase comes out of the HCD setup phase, which
proceeds something like this. The Linux driver core goes through all
devices on the PCI bus (including the USB host controller of course) and
calls the probe() function the device's driver has registered (the
host controller registered itself in its initialisation function
drivers/usb/core/uhci-hcd.c:uhci_hcd_init()). The USB host
controller driver wires up the HCD layer function
drivers/usb/core/hcd-pci.c:usb_hcd_pci_probe() to handle this probe
(see struct pci_driver uhci_pci_driver in uhci-hcd.c;
usb_hcd_pci_probe() does some generic setup, but then calls back
into the host driver start() function to do any device specific
setup).
usb_hcd_pci_probe() ends up calling
drivers/usb/core/hcd.c:usb_add_hcd() which does some generic HCD
setup and ends up calling register_root_hub().
register_root_hub() creates a new USB device and registers it with
drivers/usb/core/hub.c:usb_new_device(). usb_new_device() first
calls drivers/usb/core/config.c:usb_get_configuration which sets up
the interface (all hubs only have one interface; the interrupt interface
to notify of events on the hub) for the device before registering with
the Linux driver core via drivers/base/core/device_add().
device_add() then causes the USB bus to be rescanned.
Binding root hub to a driver
Now we can examine how a USB device gets associated with a driver. To
summarise, what needs to happen is the hub driver needs to bind to the
host controllers root hub. This illustrates the general concept of a new
device binding to a driver.
There is, believe it or not, more layers that come into play now. There
is a "generic" USB driver that handles the setup of interfaces in the
USB core. As we mentioned earlier a device has a series of end-points
grouped together into an interface, and then may have multiple
interfaces for different things. Drivers really only care about
communicating with the device at the interface level, so the USB core
takes care of getting things to this stage for you.
In drivers/usb/core/usb.c:usb_init() the final call is to
drivers/usb/core/driver.c:usb_register_device_driver(). This does
some simple wrapping of the driver, most importantly setting up
usb_probe_device() to handle any probes. It then registers this with
Linux driver core with a call to driver_register.
Remembering that drivers/usb/hub.c:usb_new_device() has called
device_add(), the driver core will now see this new device and start
probing for a driver to handle it. The USB generic driver is going to be
called, which has registered
drivers/usb/core/driver.c:usb_probe_device() as its probe function.
This converts the Linux driver core device back to a USB device (i.e.
the USB device that was registered by register_root_hub()) and calls
calls the drivers probe function
drivers/usb/core/generic.c:generic_probe().
The role of the generic driver is to get the interfaces on the device up
and running. Firstly it calls
drivers/usb/generic.c:choose_configuration() which simply reads
through the device data and chooses a sane configuration. But wait, how
does it know what is a sane configuration for the root hub? All the
information has been "faked" for the root hub in
drivers/usb/core/hcd.c:usb2_rh_dev_descriptor and the like. The root
hub details are defined by the USB specification, so these can be kept
statically.
Assuming everything is OK,
drivers/usb/core/message.c:usb_set_configuration() is called to set
up the chosen configuration. It uses the helper function
usb_control_message() to send a message to the device about what
configuration mode to go into. It then goes through the available
interfaces setting up the kernel structures, and adds them with
device_add().
Inch by inch, we are getting closer to having the USB system up and
running. When a new interface is added, the driver core will now try and
find a driver to handle it. When an interface driver is registered with
drivers/usb/core/driver.c:usb_register_driver() it sets the probe
function to drivers/usb/core/driver.c:usb_probe_interface(). So the
driver core calls this function, and the first thing it does is checks
the ID against the IDs the driver is happy to handle from the drivers
id_table. It uses usb_match_one_id() for this, which can match
the class, subclass and protocol to make sure the it will work with this
driver.
The root hub is part of the hub class, so can be handled by the hub
driver. Therefore drivers/usb/core/hub.c:hub_probe() will be called
to get the hub driver to bind with the new hub. This does some sanity
checking and calls into hub_configure(). This then does some more
general setup, but things get interesting when the interrupt end-point
is setup. The interrupt end-point on a hub will send an event whenever
something happens on the hub, such as a device being plugged in or
unplugged. This is done by creating a URB and binding it to the
end-point, asking that hub_irq be called whenever this URB is
complete (e.g. when an event is received).
New events on the hub
At this point, the system is waiting for something to happen. The root
hub is setup and listening for new events - we are ready to plug in our
device.
When this happens the host controller will raise an interrupt signalling
that one of its ports has changed state. This will be handled by
drivers/usb/host/uhci-hcd.c:uhci_irq(). This checks that the
interrupt wasn't due to an error and then calls
drivers/usb/host/uhci-q.c:uhci_scan_schedule(). This function
implements the interface between the UHCI "transfer data" messages and
the Linux URB scheme. It goes through the queues as illustrated in the
figure above and finds any complete URBs and calls their completion
function.
You may remember that the interrupt end-point of the hub was associated
with a URB that would call drivers/usb/core/hub.c:hub_irq(). The
UHCI code will go through it's queues, find that this URB is complete
and therfore call the completion function.
We previously mentioned that the kernel starts the khubd daemon to
handle hub events. We can see that hub_irq does some simple error
checking, but its real job is to notify khubd that there is a new
event on this hub.
hub_events() is the khubd daemon thread doing all the work. Once
notified the hub has new event, it goes and reads the hub status to see
what to do. A new device appearing will trigger a port change event,
which is handled by hub_port_connect_change(). This does some
initial setup of the device, but most importantly now calls
usb_new_device().
At this point, if the USB driver for this device is loaded, the device
is essentially ready to go. As with the root hub, the device will be
probed and its interfaces found with the generic driver, and then those
interfaces will be registered and any driver asked if they wish to bind
to them.
Loading drivers
The question arises, however, about how modules are dynamically loaded.
Keeping every single module for every possible USB device that may plug
into the system is clearly sub-optimal, so we wish to load a device
driver module only when required.
Most everyone is aware of udev which handles /dev device nodes
these days. udev sits around listening for uevents which get
sent to it via the kernel. These uevents get sent via netlink,
which is like Unix sockets but different. To get uevent messages all
you need to do is open a PF_NETLINK socket to the
NETLINK_KOBJECT_UEVENT "port", e.g. as the code below extract from
udev does.
memset(&snl, 0x00, sizeof(struct sockaddr_nl));
snl.nl_family = AF_NETLINK;
snl.nl_pid = getpid();
snl.nl_groups = 1;
uevent_netlink_sock = socket(PF_NETLINK, SOCK_DGRAM, NETLINK_KOBJECT_UEVENT);
if (uevent_netlink_sock == -1) {
err("error getting socket: %s", strerror(errno));
return -1;
}
So we have udev sitting around up in userspace waiting for messages
that come from the kernel (as a side note, if
/sys/kernel/uevent_helper is filled in with a path that will be run
and receive the events with environment variables set; this is useful in
early boot before udev has started.
Thus we want to get a message out to udev that there is a new USB
interface around, and it should try and load a module to bind to it.
We previously identified
drivers/usb/core/message.c:usb_set_configuration() as reading the
interfaces for a device and registering them with the driver core. When
this registers the interface, it also registers a uevent helper
drivers/usb/core/message.c:usb_if_uevent(). This function gets
called by the Linux driver core when the driver is added into the driver
hierarchy. It adds some information to the uevent:
if (add_uevent_var(envp, num_envp, &i,
buffer, buffer_size, &length,
"INTERFACE=%d/%d/%d",
alt->desc.bInterfaceClass,
alt->desc.bInterfaceSubClass,
alt->desc.bInterfaceProtocol))
return -ENOMEM;
if (add_uevent_var(envp, num_envp, &i,
buffer, buffer_size, &length,
"MODALIAS=usb:v%04Xp%04Xd%04Xdc%02Xdsc%02Xdp%02Xic%02Xisc%02Xip%02X",
le16_to_cpu(usb_dev->descriptor.idVendor),
le16_to_cpu(usb_dev->descriptor.idProduct),
le16_to_cpu(usb_dev->descriptor.bcdDevice),
usb_dev->descriptor.bDeviceClass,
usb_dev->descriptor.bDeviceSubClass,
usb_dev->descriptor.bDeviceProtocol,
alt->desc.bInterfaceClass,
alt->desc.bInterfaceSubClass,
alt->desc.bInterfaceProtocol))
return -ENOMEM;
udev now has all the information required ask modprobe to load a
module, if it can. The rule on my system looks something like:
# load the drivers
ENV{MODALIAS}=="?*", RUN+="/sbin/modprobe --use-blacklist $env{MODALIAS}"
Now, all going well, modprobe loads an appropriate module based on
the vendor id, etc. Loading the driver causes a re-scan of the USB bus
and the driver will be probed to see if wants to handle any of the
unbinded USB devices (using the same procedure as was done setting up
the root hub). It should take over control of the device, and that's it
your USB device is up and running!
Simple!
Handy resources if you want to know more: Linux Device
Drivers, USB2
Specification, UHCI Design
Guide.