I recently finished The Race for a New Game Machine: Creating the Chips Inside the XBox 360 and the Playstation 3 (David Shippy and Mickie Phipps); an interesting insight into the processor development process from some of the lead architects.
The executive summary is : Sony, Toshiba and IBM (STI) decided to get together to create the core of the Playstation 3 — the Cell processor. Sony, with their graphics and gaming experience, would do the Synergistic Processing Elements; extremely fast but limited sub-units specialising in doing 3D graphics and physics work (i.e. great for games). IBM would do a Power based core that handled the general purpose computing requirements.
The twist comes when Microsoft came along to IBM looking for the Xbox 360 processor, and someone at IBM mentioned the Power core that was being worked on for the Playstation. Unsurprisingly, the features being built for the Playstaion also interested Microsoft, and the next thing you know, IBM is working on the same core for Microsoft and Sony at the same time, without telling either side.
This whole chain of events makes for a very interesting story. The book is written for a general audience, but you'll probably get the most out of it if you already have some knowledge of computer architecture; if you're trying to understand some of the concepts referred to from the two line descriptions you'll get a bit lost (H&P it is not).
The only small criticism is that it sometimes falls into reading a bit like a long LinkedIn recommendation. However, the book is very well paced, and throws in just enough technical tidbits amongst the corporate and personal dramas to make it a very fun read.
One thing that is talked about a bit is the fan-out of four (FO4) metric used in the designers quest to push the chip as fast as possible (and, as mentioned many times in the book, faster than what Intel could do!). I thought it might be useful to expand on this interesting metric a bit.
FO4
One problem facing chip architects is that, thanks to Moore's Law, it is hard to find a constant to compare design versus implementation. For example, you may design an amazing logic-block to factor large integers into products of prime numbers, but somebody else with better fabrication facilities might be able to essentially brute-force a better solution by producing faster hardware using a much less innovative design.
Some metric is needed that can compare the two designs discounting who has the better fabrication process. This is where the FO4 comes in.
When you change the input to a logic gate, it is not like it magically flips the output to the correct level instantaneously. There is a latency while everything settles to its correct level — the gate delay. The more gates connected to the output of a gate the more current required, which has additional effects on latency. The FO4 latency is defined as the time required to flip an inverter gate connected to (fanned-out) to four other inverter gates.
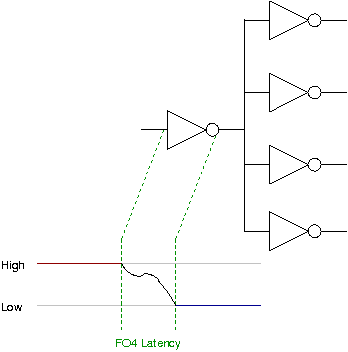
Thus you can describe the latency of other logic blocks in multiples of FO4 latencies. As this avoids measuring against wall-time it is an effective description of the relative efficiency of logic designs. For example, you may calculate that your factoriser has a latency of 100 FO4. Just because someone else's 200 FO4 factoriser gets a result a few microseconds faster thanks to their fancy ultra-low-FO4-latency fabrication process, you can still show that your design, at least a priori, is better.
The book refers several times to efforts to reduce the FO4 of the processor as much as possible. The reason this is important in this context is that the maximum latency on the critical path will determine the fastest clock speed you can run the processor at. For reasons explained in the book high clock speed was a primary goal, so every effort had to be made to reduce latencies.
All modern processors operate as a production line, with each stage doing some work and passing it on to the next stage. Clearly the slowest stage determines the maximum speed that the production line can run at (weakest link in the chain and all that). For example, if you clock at 1Ghz, that means each cycle takes 1 nanosecond (1s / 1,000,000,000Hz). If you have a F04 latency of say, 10 picoseconds, that means any given stage can have a latency of no more than 100 FO4 — otherwise that stage would not have enough time to settle and actually produce the correct result.
Thus the smaller you can get the FO4 latencies of your various stages, the higher you can safely up the clock speed. One way around long latencies might be to split-up your logic into smaller stages, making a much longer pipeline (production line). For example, split your 100 FO4 block into two 50 FO4 stages. You can now clock the processor higher, but this doesn't necessarily mean you'll get actual results out the end of the pipeline any faster (as Intel discovered with the Pentium 4 and it's notoriously long pipelines and corresponding high clock rates).
Of course, this doesn't even begin to describe the issues with superscalar design, instruction level parallelism, cache interaction and the myriad of other things the architects have to consider.
Anyway, after reading this book I guarantee you'll have an interesting new insight the next time you fire-up Guitar Hero.