I've previously mentioned the gate page on Linux, but I thought a little more information might be useful.
The reason why system calls are so slow on x86 goes back to the ingenious but complicated segmentation scheme used by the processor. The original reason for segmentation was to be able to use more than the 16 bits available in a register for an address, as illustrated below.
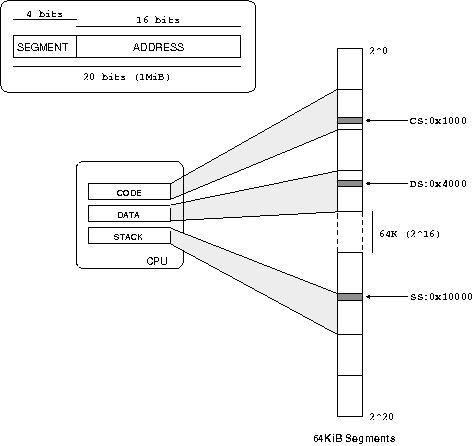
When x86 moved to 32 bit registers, the segmentation scheme remained but in a different format.
Rather than fixed segment sizes, segments are allowed to be any size. This means the processor needs to keep track of all these different segments and their sizees, which it does descriptors. The segment descriptors available to everyone are kept in the global descriptor table or GDT for short. Each process has a number of registers which point to entries in the GDT; these are the segments the process can access (there are also local descriptor tables, and it all interacts with task state segments, but that's not important now).
The situation is illustrated below.
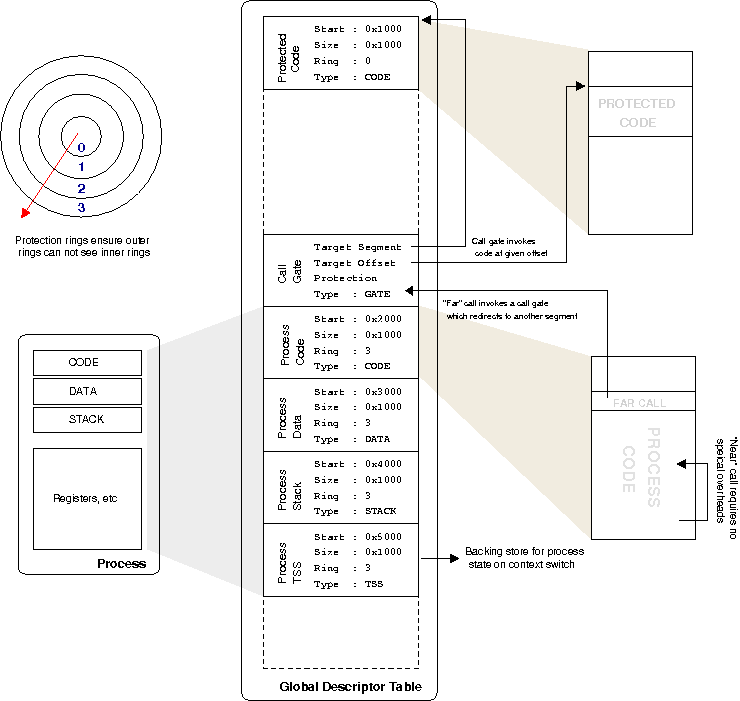
Since the processor knows what segments of memory the currently running process can access, it can enforce protection and ensure the process doesn't touch anything it is not supposed to. If it does go out of bounds, you receive a segmentation fault, which most programmers are familiar with.
The interesting bit comes when you want to make calls into code that resides in another segment. To implement a secure system, we can give segments a certain permission value. x86 does this with rings, where ring 0 is the highest permission, ring 3 is the lowest, and inner rings can access outer rings but not vice-versa.
Like any good nightclub, once you're inside "club ring 0" you can do anything you want. Consequently there's a bouncer on the door, in the form of a call gate. When ring 3 code wants to jump into ring 0 code, you have to go through the call gate. If you're on the door list, the processor gets bounced to a certain offset of code within the ring 0 segment.
This allows a whole hierarchy of segments and permissions between them. You might have noticed a cross segment call sounds exactly like a system call. If you've ever looked at Linux x86 assembly the standard way to make a system call is int 0x80, which raises interrupt 0x80. An interrupt stops the processor and goes to an interrupt gate, which then works the same as a call gate -- it bounces you off to some other area of code assuming you are allowed.
The problem with this scheme is that it is slow. It takes a lot of effort to do all this checking, and many registers need to be saved to get into the new code. And on the way back out, it all needs to be restored again.
On a modern system, the only thing that really happens with all this fancy segmentation switching is system calls, which essentially switch from mode 3 (userspace) to mode 0 and jump to the system call handler code inside the kernel. Thus sysenter (and sysexit to get back) speed up the whole process over an int 0x80 call by removing the general nature of a far call (i.e. the possibility of going to any segment, with any ring level) and restricting you to going to ring 0 code at a specific segment and offset, as stored in registers.
Because there are so many less options, the whole process can be speed up, and hence we have a fast system call. The other thing to note is that state is not preserved when the kernel gets control. The kernel has to be careful to not to destory state, but it also means it is free to only save as little state as is required to do the job, so can be much more efficient about it. If you're thinking "wow that sounds like insert favourite RISC processor", you're probably right.
The x86 truly is a weird and wonderful machine!